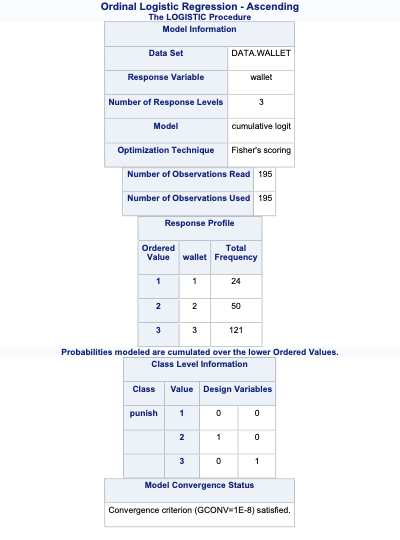
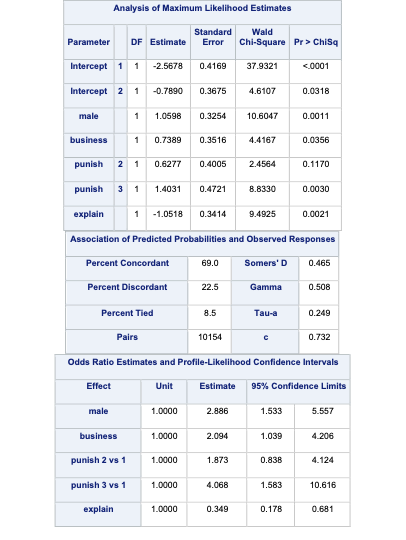
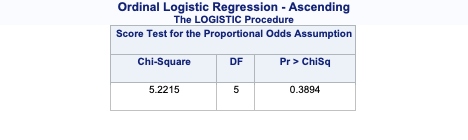
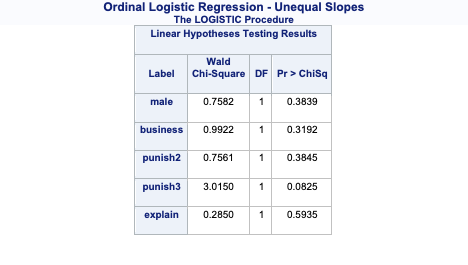
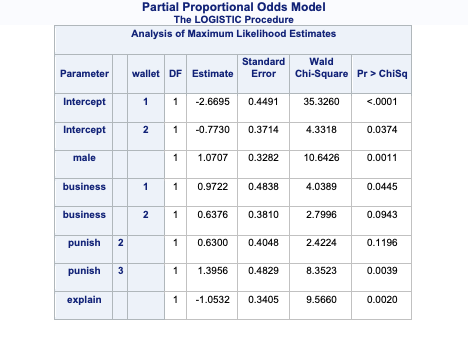
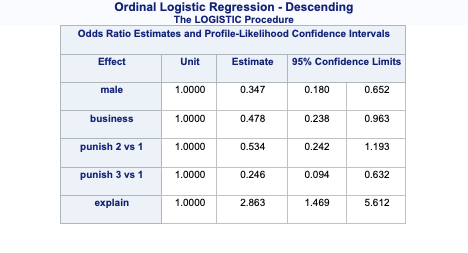
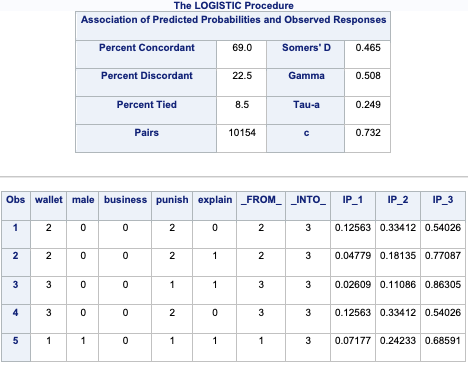
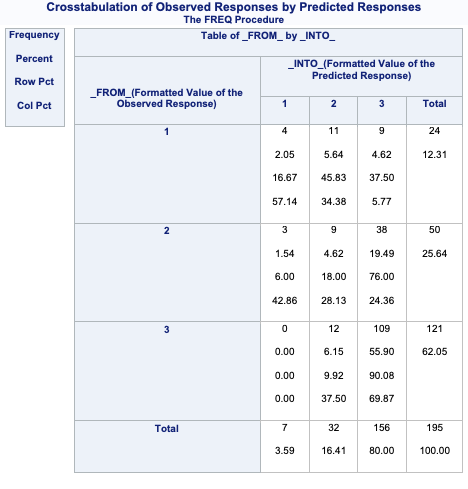
array([[0.12450334, 0.32805765, 0.54743901],
[0.036921 , 0.18849781, 0.77458119],
[0.01561104, 0.11560551, 0.86878345],
[0.12450334, 0.32805765, 0.54743901],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.036921 , 0.18849781, 0.77458119],
[0.04485704, 0.20870065, 0.74644231],
[0.14517644, 0.34533921, 0.50948435],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.0643303 , 0.24921245, 0.68645725],
[0.036921 , 0.18849781, 0.77458119],
[0.24791909, 0.38985644, 0.36222447],
[0.66123288, 0.26515445, 0.07361267],
[0.01561104, 0.11560551, 0.86878345],
[0.30390383, 0.39469207, 0.30140409],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.336322 , 0.39309468, 0.27058332],
[0.06492792, 0.25029522, 0.68477686],
[0.0643303 , 0.24921245, 0.68645725],
[0.4834516 , 0.35596896, 0.16057944],
[0.30390383, 0.39469207, 0.30140409],
[0.30390383, 0.39469207, 0.30140409],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.12547786, 0.328959 , 0.54556314],
[0.06492792, 0.25029522, 0.68477686],
[0.12450334, 0.32805765, 0.54743901],
[0.18947167, 0.3716158 , 0.43891253],
[0.24487445, 0.389275 , 0.36585056],
[0.12450334, 0.32805765, 0.54743901],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.12450334, 0.32805765, 0.54743901],
[0.14517644, 0.34533921, 0.50948435],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.0643303 , 0.24921245, 0.68645725],
[0.41148377, 0.37950073, 0.20901549],
[0.30390383, 0.39469207, 0.30140409],
[0.036921 , 0.18849781, 0.77458119],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.18947167, 0.3716158 , 0.43891253],
[0.336322 , 0.39309468, 0.27058332],
[0.18947167, 0.3716158 , 0.43891253],
[0.41332678, 0.37901579, 0.20765743],
[0.01561104, 0.11560551, 0.86878345],
[0.09410744, 0.2947468 , 0.61114576],
[0.01561104, 0.11560551, 0.86878345],
[0.0643303 , 0.24921245, 0.68645725],
[0.01561104, 0.11560551, 0.86878345],
[0.04485704, 0.20870065, 0.74644231],
[0.0643303 , 0.24921245, 0.68645725],
[0.06492792, 0.25029522, 0.68477686],
[0.18947167, 0.3716158 , 0.43891253],
[0.24941928, 0.3901297 , 0.36045102],
[0.24941928, 0.3901297 , 0.36045102],
[0.24487445, 0.389275 , 0.36585056],
[0.12547786, 0.328959 , 0.54556314],
[0.01561104, 0.11560551, 0.86878345],
[0.24791909, 0.38985644, 0.36222447],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.0643303 , 0.24921245, 0.68645725],
[0.14517644, 0.34533921, 0.50948435],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.04485704, 0.20870065, 0.74644231],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.036921 , 0.18849781, 0.77458119],
[0.336322 , 0.39309468, 0.27058332],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.14517644, 0.34533921, 0.50948435],
[0.01561104, 0.11560551, 0.86878345],
[0.14517644, 0.34533921, 0.50948435],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.04485704, 0.20870065, 0.74644231],
[0.036921 , 0.18849781, 0.77458119],
[0.14517644, 0.34533921, 0.50948435],
[0.30390383, 0.39469207, 0.30140409],
[0.06492792, 0.25029522, 0.68477686],
[0.14517644, 0.34533921, 0.50948435],
[0.06492792, 0.25029522, 0.68477686],
[0.66123288, 0.26515445, 0.07361267],
[0.14517644, 0.34533921, 0.50948435],
[0.41332678, 0.37901579, 0.20765743],
[0.09410744, 0.2947468 , 0.61114576],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.41148377, 0.37950073, 0.20901549],
[0.01561104, 0.11560551, 0.86878345],
[0.0643303 , 0.24921245, 0.68645725],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.4834516 , 0.35596896, 0.16057944],
[0.06492792, 0.25029522, 0.68477686],
[0.04485704, 0.20870065, 0.74644231],
[0.24791909, 0.38985644, 0.36222447],
[0.24338899, 0.38897811, 0.3676329 ],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.01561104, 0.11560551, 0.86878345],
[0.14517644, 0.34533921, 0.50948435],
[0.0643303 , 0.24921245, 0.68645725],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.14517644, 0.34533921, 0.50948435],
[0.06492792, 0.25029522, 0.68477686],
[0.14517644, 0.34533921, 0.50948435],
[0.0643303 , 0.24921245, 0.68645725],
[0.01561104, 0.11560551, 0.86878345],
[0.47771769, 0.3581683 , 0.16411401],
[0.18947167, 0.3716158 , 0.43891253],
[0.18947167, 0.3716158 , 0.43891253],
[0.036921 , 0.18849781, 0.77458119],
[0.14517644, 0.34533921, 0.50948435],
[0.24791909, 0.38985644, 0.36222447],
[0.01561104, 0.11560551, 0.86878345],
[0.14517644, 0.34533921, 0.50948435],
[0.0643303 , 0.24921245, 0.68645725],
[0.1440992 , 0.34452838, 0.51137242],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.18947167, 0.3716158 , 0.43891253],
[0.0643303 , 0.24921245, 0.68645725],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.30390383, 0.39469207, 0.30140409],
[0.24487445, 0.389275 , 0.36585056],
[0.06492792, 0.25029522, 0.68477686],
[0.18947167, 0.3716158 , 0.43891253],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.336322 , 0.39309468, 0.27058332],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.18947167, 0.3716158 , 0.43891253],
[0.09171494, 0.29163418, 0.61665088],
[0.24487445, 0.389275 , 0.36585056],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.41332678, 0.37901579, 0.20765743],
[0.06492792, 0.25029522, 0.68477686],
[0.0643303 , 0.24921245, 0.68645725],
[0.4834516 , 0.35596896, 0.16057944],
[0.01561104, 0.11560551, 0.86878345],
[0.14517644, 0.34533921, 0.50948435],
[0.01561104, 0.11560551, 0.86878345],
[0.12450334, 0.32805765, 0.54743901],
[0.06492792, 0.25029522, 0.68477686],
[0.47771769, 0.3581683 , 0.16411401],
[0.30390383, 0.39469207, 0.30140409],
[0.01561104, 0.11560551, 0.86878345],
[0.41148377, 0.37950073, 0.20901549],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686],
[0.01561104, 0.11560551, 0.86878345],
[0.06492792, 0.25029522, 0.68477686],
[0.30390383, 0.39469207, 0.30140409],
[0.09171494, 0.29163418, 0.61665088],
[0.12450334, 0.32805765, 0.54743901],
[0.14517644, 0.34533921, 0.50948435],
[0.09171494, 0.29163418, 0.61665088],
[0.24791909, 0.38985644, 0.36222447],
[0.336322 , 0.39309468, 0.27058332],
[0.09410744, 0.2947468 , 0.61114576],
[0.12547786, 0.328959 , 0.54556314],
[0.01561104, 0.11560551, 0.86878345],
[0.24941928, 0.3901297 , 0.36045102],
[0.01561104, 0.11560551, 0.86878345],
[0.14517644, 0.34533921, 0.50948435],
[0.06492792, 0.25029522, 0.68477686],
[0.06492792, 0.25029522, 0.68477686]])